Тестовое задание: Crowd / Технический менеджер проектов
Анализ лога краудсорсингового проекта по бинарной разметке URL (workflow REGION_MARKUP).
Цель — оценить качество разметки, найти проблемные контрольные задания и посчитать ключевые метрики проекта.
Содержание
Задание 1. Привести данные к удобному формату
Исходный TSV-файл содержит JSON-поля, «сжатые» в строки, и Unix-таймстемпы. Чтобы данные стали пригодны для анализа, нужно: распарсить JSON, перевести времена в datetime и развернуть страницы-ассайменты в длинный формат «одна строка = одно микро-задание».
Ключевые шаги
# 1. Загрузка
df = pd.read_csv(SRC, sep="\t")
# 2. Unix-секунды -> datetime
for col in ("assignment_skip_time", "assignment_start_time", "assignment_submit_time"):
df[col] = df[col].apply(lambda ts: pd.to_datetime(int(ts), unit="s", utc=True)
if pd.notna(ts) else pd.NaT)
# 3. Длительность работы над страницей
df["duration_sec"] = (df["assignment_submit_time"] - df["assignment_start_time"]).dt.total_seconds()
# 4. JSON-поля
df["solutions_parsed"] = df["assignment_raw_solutions"].apply(json.loads)
df["tasks_parsed"] = df["task_suite_raw_tasks"].apply(json.loads)
# 5. Длинный формат: одна строка = одно задание внутри страницы
rows = []
for _, r in df.iterrows():
for i, task in enumerate(r["tasks_parsed"]):
url = task["input_values"]["input"]["view"]["data"]["region_markup"]["url"]
known = task.get("known_solutions")
gold = known[0]["output_values"]["result"] if known else None
ans = r["solutions_parsed"][i]["output_values"].get("result") if i < len(r["solutions_parsed"]) else None
rows.append({
"assignment_id": r["assignment_assignment_id"],
"worker_id": r["worker_id"],
"task_index": i,
"url": url,
"is_honeypot": bool(known),
"gold_answer": gold,
"worker_answer": ans,
"is_correct": None if not known else (ans == gold),
})
tasks_long = pd.DataFrame(rows)Сводка по данным
| Показатель | Значение |
|---|---|
| Страниц в логе | 21 437 |
| Микро-заданий | 203 963 |
| Из них контрольных (ханипотов) | 31 063 (15,2%) |
| Уникальных контрольных URL | 13 358 |
| Исполнителей | 2 258 |
| Распределение ответов | yes 94 335 / no 72 604 / not_working 9 060 / NaN 27 964 |
assignments_clean.csv (по странице) и
tasks_long.csv (по микро-заданию). Длинная таблица — основа всех расчётов на шагах 2–3.
Уже на этом шаге заметно, что (1) у воркеров есть третья кнопка not_working помимо да/нет;
(2) число пустых ответов (27 964) почти точно равно 10 × число EXPIRED-страниц (2 815) — то есть на
истёкших страницах ответов нет вовсе.
Задание 2. «Сложные» и «неоднозначные» контрольные задания
Контрольное задание идентифицируем по URL. Группируем все показы ханипота, считаем долю верных ответов и баланс «yes/no». Чтобы статистика не шумела, фильтруем URL с ≥ 5 показов — таких 268.
Метрики
accuracy_yes_no— доля верных ответов среди {yes, no}. Ответыnot_workingисключаем, потому что это «техническая» реакция (сайт не открылся), а не смысловая ошибка.ambiguity_score = 1 − 2·|yes_share − 0.5|— 1.0 = идеально 50/50.entropy_bits— двоичная энтропия ответов yes/no.
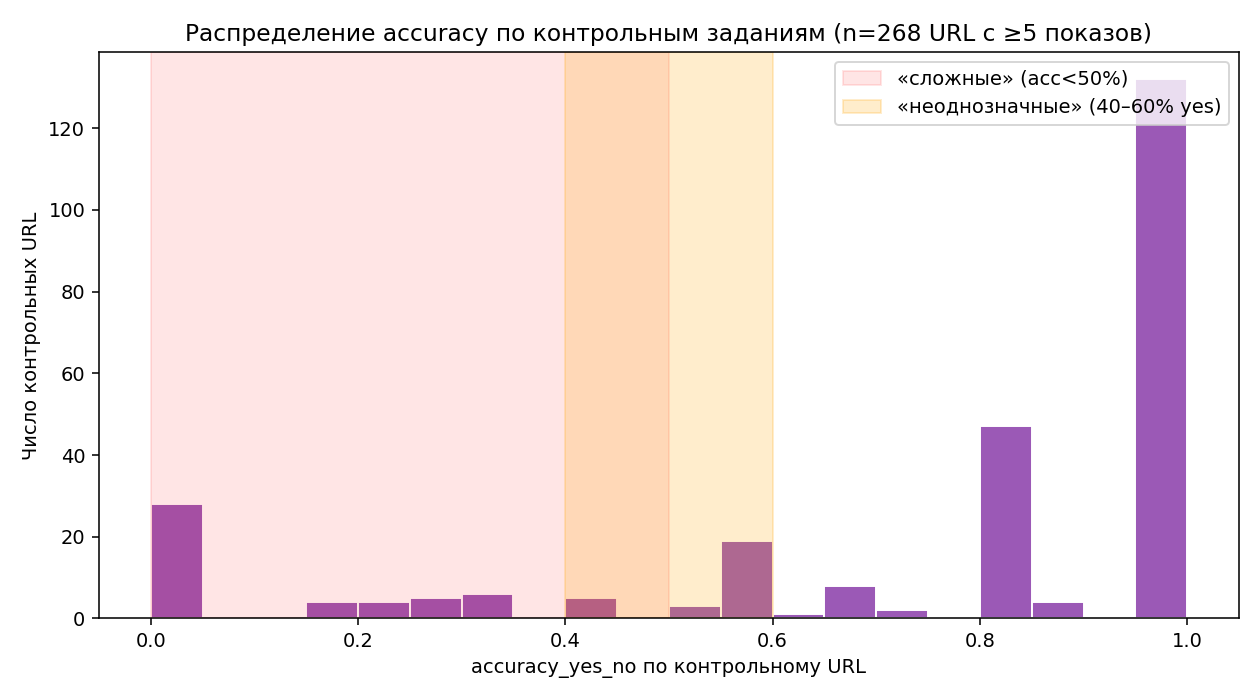
| Бакет accuracy | URL | Доля |
|---|---|---|
| 0–20% | 32 | 11,9% |
| 20–40% | 16 | 6,0% |
| 40–60% | 22 | 8,2% |
| 60–80% | 36 | 13,4% |
| 80–100% | 158 | 59,0% |
Доля «сложных» (acc < 50%): 17,9%. Доля «неоднозначных» (40–60% yes): 10,1%.
Топ «сложных» (примеры из 32 URL с 0% accuracy)
| URL | Gold | Показов | yes | no | not_working | accuracy |
|---|---|---|---|---|---|---|
| svarka-piter.ru | no | 6 | 6 | 0 | 0 | 0% |
| food-service.ru | yes | 6 | 0 | 6 | 0 | 0% |
| vip-phones.ru | not_working | 5 | 5 | 0 | 0 | 0% |
| faridkamal.pro | not_working | 6 | 6 | 0 | 0 | 0% |
| gazballon-nizhniy-tagil.ru | no | 8 | 8 | 0 | 0 | 0% |
| efsmoscow.ru | no | 7 | 7 | 0 | 0 | 0% |
| myshop-bei517.myinsales.ru | not_working | 6 | 6 | 0 | 0 | 0% |
Полный список — honeypot_hardest.csv.
Топ «неоднозначных» (yes/no близко к 50/50)
| URL | Gold | yes | no | yes_share | entropy, бит |
|---|---|---|---|---|---|
| giftarcher.ru | no | 3 | 3 | 50% | 1.00 |
| tvoya-vaza.ru | no | 3 | 3 | 50% | 1.00 |
| бир.рф | yes | 3 | 3 | 50% | 1.00 |
| klassikashop.ru | yes | 4 | 3 | 57% | 0.99 |
| myxbag.ru | no | 3 | 4 | 43% | 0.99 |
Полный список — honeypot_most_ambiguous.csv.
not_working,
на которых все воркеры ставят yes, — кандидаты на удаление в первую очередь, т.к. они
штрафуют добросовестную работу.
Задание 3. Дополнительные метрики проекта
5 метрик, главная (M1) — качество разметки.
M1. Honeypot accuracy — главная метрика качества
| Показатель | Значение |
|---|---|
| Project accuracy (yes/no, без not_working) | 74,4% |
| Project accuracy (строгая, с not_working) | 71,9% |
| Медиана accuracy по воркерам (n=1 061 с ≥10 ханипотами) | 78% |
| Доля воркеров с accuracy < 70% (кандидаты на бан) | 16,6% |
| Доля воркеров с accuracy ≥ 90% (доверенные) | 2,9% |
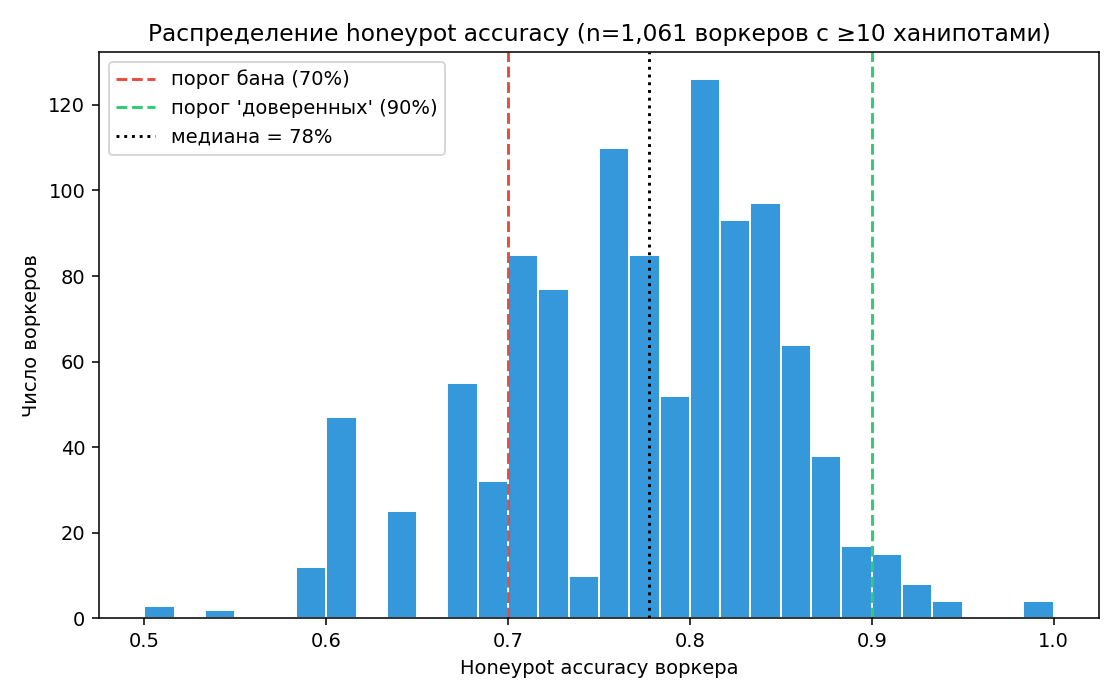
Польза: прямой индикатор корректности разметки. 74% — это средне-низко для бинарной задачи; обычно проект считается «здоровым» при ≥85%. Гистограмма унимодальная (мода ~80%), без явного второго пика «ботов» у нуля — массового мошенничества нет, но левый хвост (≈170 воркеров с acc < 70%) тянет среднее вниз.
M2. Status mix — здоровье воркфлоу
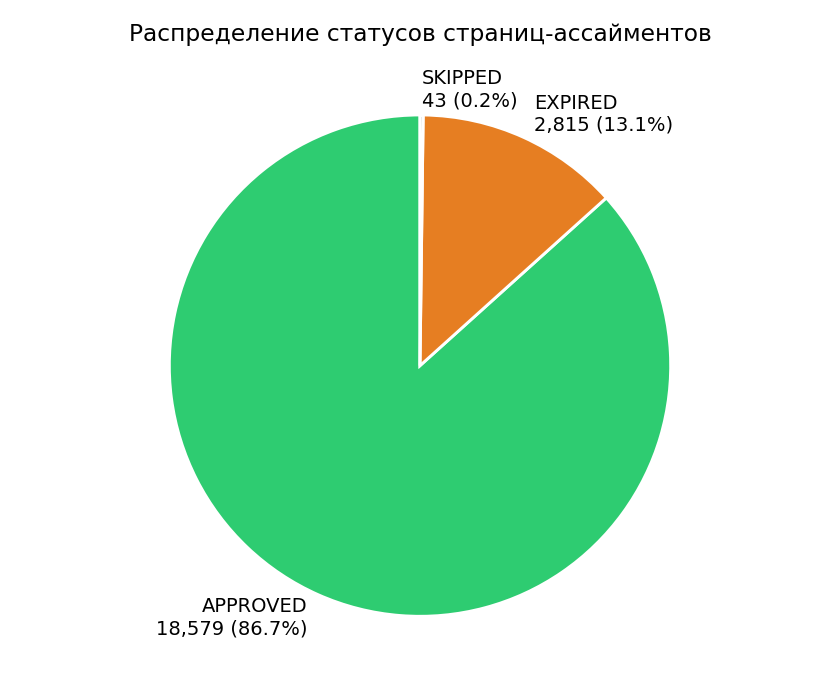
| Статус | Страниц | Доля |
|---|---|---|
| APPROVED | 18 579 | 86,7% |
| EXPIRED | 2 815 | 13,1% |
| SKIPPED | 43 | 0,2% |
Польза: EXPIRED-rate 13% — ощутимая утечка. SUBMITTED/REJECTED отсутствуют — значит, отдельной модерации после автоприёма по ханипотам нет. Это означает, что 86,7% APPROVED не равно 86,7% хороших ответов: сюда же попадают страницы воркеров с accuracy 60–70%.
M3. Throughput — производительность
| Показатель | Значение |
|---|---|
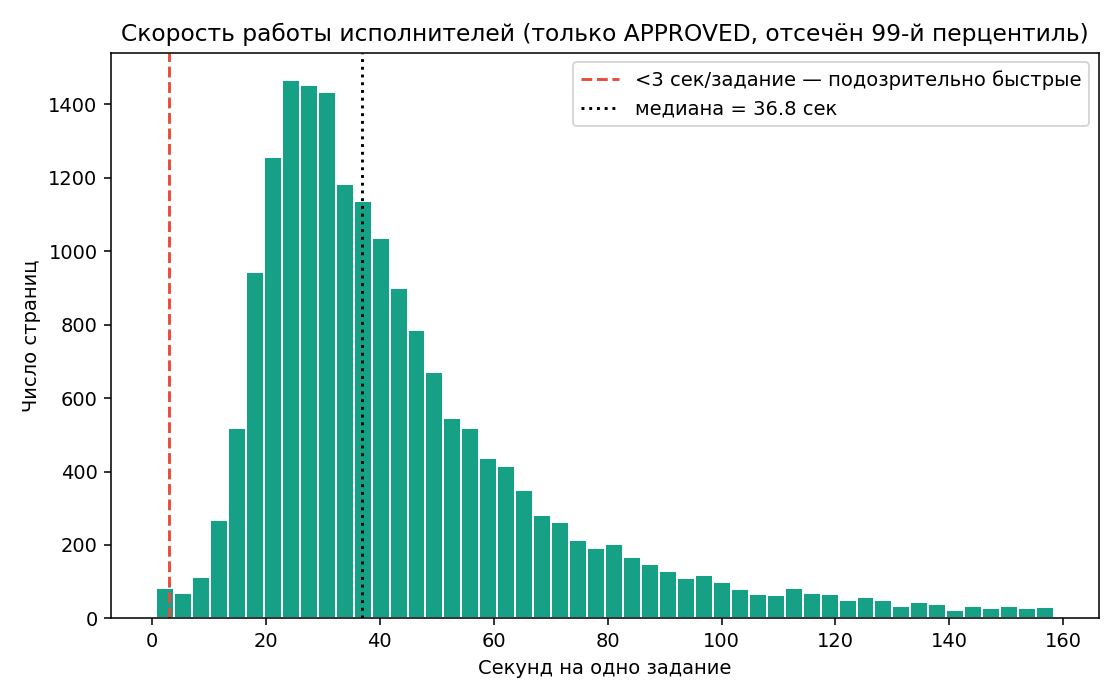
| Медиана длительности страницы (10 заданий) | 349 сек |
| Медиана сек/задание | 36,8 сек |
| 90-й перцентиль сек/задание | 82 сек |
| Доля страниц с < 3 сек/задание (random clicking) | 0,36% |
Польза: показывает, что задание реально трудоёмкое (~37 сек на URL — успеть открыть сайт и оценить). Подозрительно быстрых страниц мало — массового «кликания» нет, проблема качества лежит в плоскости понимания задачи, а не скорости.
M4. Worker concentration — устойчивость пула
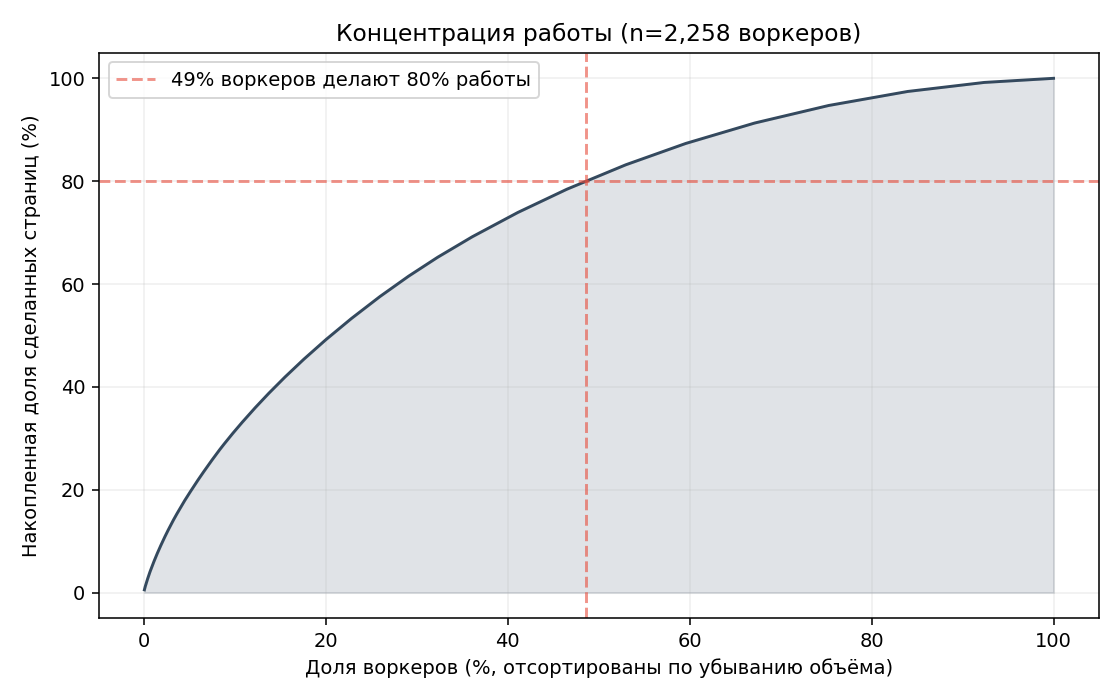
| Показатель | Значение |
|---|---|
| Воркеров делает 50% объёма | 465 (20,6%) |
| Воркеров делает 80% объёма | 1 098 (48,6%) |
| Топ-1 воркер | 114 страниц = 0,5% объёма |
Польза: работа размазана — bus-factor низкий, нет «ключевых» воркеров, потеря которых сломает проект. Это плюс с точки зрения устойчивости, но минус с точки зрения управляемости качеством: каждый воркер делает в среднем 9,5 страниц — мало для надёжной оценки accuracy на новичках.
M5. Honeypot density
| Показатель | Значение |
|---|---|
| Доля ханипотов в показанных заданиях | 15,2% |
| Ханипотов на страницу: медиана / среднее / max | 1 / 1,45 / 2 |
Польза: проверка корректности настройки контроля. 15% — стандартное значение (обычно 10–20%); у нас есть достаточно сигнала для оценки воркеров (в среднем 1–2 контрольных на 10 заданий).
Сводная таблица всех метрик
| Метрика | Значение | Сигнал |
|---|---|---|
| M1. Honeypot accuracy (проект) | 74,4% | низковато (норма 85%+) |
| M1. Доля воркеров с accuracy < 70% | 16,6% | требуется чистка |
| M2. APPROVED rate | 86,7% | OK |
| M2. EXPIRED rate | 13,1% | повышенный |
| M3. Median sec/task | 36,8 сек | норма |
| M3. < 3 сек/task (фрод) | 0,36% | OK |
| M4. 80% работы делают | 49% воркеров | здоровое распределение |
| M5. Honeypot density | 15,2% | в норме |
Итоговый вывод
-
Данные приведены к удобному формату: два CSV (
assignments_clean.csv,tasks_long.csv) с распарсенными JSON и человекочитаемыми временами; готовы для любыхgroupbyи визуализации. - Сложные/неоднозначные ханипоты найдены: 48 URL с accuracy < 50% (из них 32 с 0% — с большой вероятностью неверный gold) и 27 URL с расщеплением 40–60%. Эти 75 URL — приоритет для ревизии командой контроля качества.
-
Качество проекта 74% — ниже бенчмарка (~85%). Главные рычаги для роста:
- ревизия gold у проблемных ханипотов уберёт ложные штрафы и поднимет accuracy воркеров без их участия;
- бан/перенаправление 16,6% слабых воркеров поднимет среднее;
- сокращение 13% EXPIRED-страниц через более короткие тайм-ауты или более привлекательную оплату ускорит конвейер.
Код и артефакты
Полный код, исходный TSV и промежуточные CSV — в репозитории. Скрипты разбиты по заданиям:
task1_normalize.py— парсинг JSON, развёртка в длинный форматtask2_honeypots.py— поиск сложных и неоднозначных контрольных заданийtask3_metrics.py— расчёт 5 метрикtask4_charts.py— генерация PNG-графиков
Артефакты в data/:
metrics_summary.csv ·
honeypot_hardest.csv ·
honeypot_most_ambiguous.csv ·
worker_quality.csv ·
honeypot_stats_all.csv ·
assignments_clean.csv